
What Is Retrieval Augmented Generation (RAG)?
Retrieval augmented generation (RAG) is an artificial intelligence technique that combines the strengths of retrieval-based and generative language models. RAG systems retrieve relevant information from external knowledge sources and use it to augment the input prompts given to a generative language model. This allows the model to produce more accurate, relevant and up-to-date responses compared to relying solely on the knowledge it was initially trained on.
The idea behind RAG is to provide language models with access to vast repositories of information to help them answer questions and generate text more effectively. By retrieving passages relevant to the given prompt and using them as additional context, RAG enables language models to draw upon a much larger knowledge base. This mitigates issues like hallucination and outdated information that plague standard language models.
RAG has emerged as a powerful approach for building applications like question-answering systems, chatbots, and knowledge base querying tools. It allows organizations to leverage their own proprietary data alongside pretrained language models. RAG makes it possible to deploy capable AI systems without the immense cost and effort of training a model from scratch on domain-specific data.
What Are the Components of RAG Systems
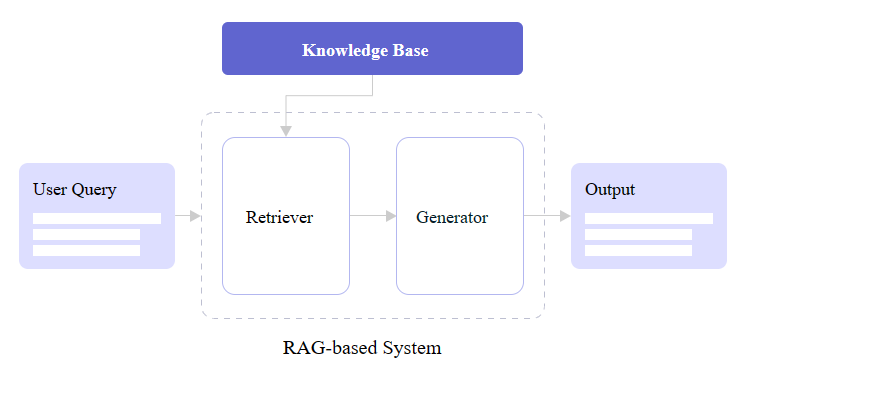
A RAG system consists of several components that work together to retrieve relevant information and generate informed responses:
Knowledge Corpus:
The foundation of a RAG system is a large corpus of text data that serves as the external knowledge source. This can include websites, books, articles, documentation, or any other relevant text data. The corpus should be comprehensive enough to cover a wide range of topics and provide sufficient information to answer various queries. The quality and scope of the knowledge corpus directly impact the performance of the RAG system.
Indexer:
To make the retrieval process efficient, the knowledge corpus needs to be indexed. The indexer component preprocesses the text data and builds an index that maps each passage to a dense vector representation. This is typically done using an encoder model that converts the text into fixed-length vectors capturing the semantic meaning. The indexer may also perform tasks like text cleaning, tokenization, and filtering to improve the quality of the index.
Retriever:
The retriever component is responsible for finding the most relevant passages from the indexed knowledge corpus for a given query. It takes the user’s query as input and converts it into a dense vector representation using the same encoder as the indexer. Then, it performs a similarity search to find the passage vectors that are most similar to the query vector.
The choice of similarity search algorithm is crucial for the retriever’s performance. Maximum Inner Product Search (MIPS) is commonly used, which finds the passage vectors that have the highest dot product with the query vector. This allows for efficient retrieval even from large indexes. The retriever may also employ techniques like term expansion, query rewriting, or multi-step retrieval to improve the relevance of the retrieved passages.
Reranker:
In some RAG architectures, a reranker component is used to further refine the retrieved passages. The reranker takes the top-k passages returned by the retriever and scores them based on their relevance to the query. This helps prioritize the most informative and pertinent passages.
The reranker often uses more sophisticated models, such as cross-attention transformers, to assess the relevance between the query and each passage in more depth. It may consider factors like semantic similarity, information overlap, and coherence to assign relevance scores. The reranked passages are then passed to the generator.
Generator:
The generator component is responsible for producing the final natural language response based on the original query and the retrieved passages. It is typically a large pretrained language model, such as GPT-3, BERT, or T5, that has been fine-tuned on the specific task.
The generator takes the query and the retrieved passages as input, often concatenated together with special separator tokens. It then generates the response using the language modeling capabilities of the pretrained model. The generator is trained to attend to both the query and the retrieved information to produce a relevant and coherent response.
The generator may employ techniques like attention mechanisms, copy mechanisms, or content planning to effectively integrate the retrieved information into the generated text. It may also use decoding strategies like beam search, top-k sampling, or nucleus sampling to control the quality and diversity of the generated responses.
Response Processor:
In some RAG systems, a final response processing step is applied to the generated text. This can include tasks like filtering out irrelevant or redundant information, truncating the response to a desired length, or applying safety checks to prevent harmful or biased content.
The response processor may also involve human feedback or oversight to ensure the quality and appropriateness of the generated responses. This can help catch errors, misinformation, or offensive content before it is returned to the user.
By combining these components effectively, RAG systems are able to retrieve relevant information from large knowledge corpora and generate informed, accurate, and fluent responses to a wide range of queries. The specific implementation details and architectures may vary across RAG systems, but these core components form the backbone of the retrieval augmented generation approach.
How Does Retrieval Augmented Generation Work?
Retrieval augmented generation (RAG) works by integrating information retrieval capabilities into language generation models.
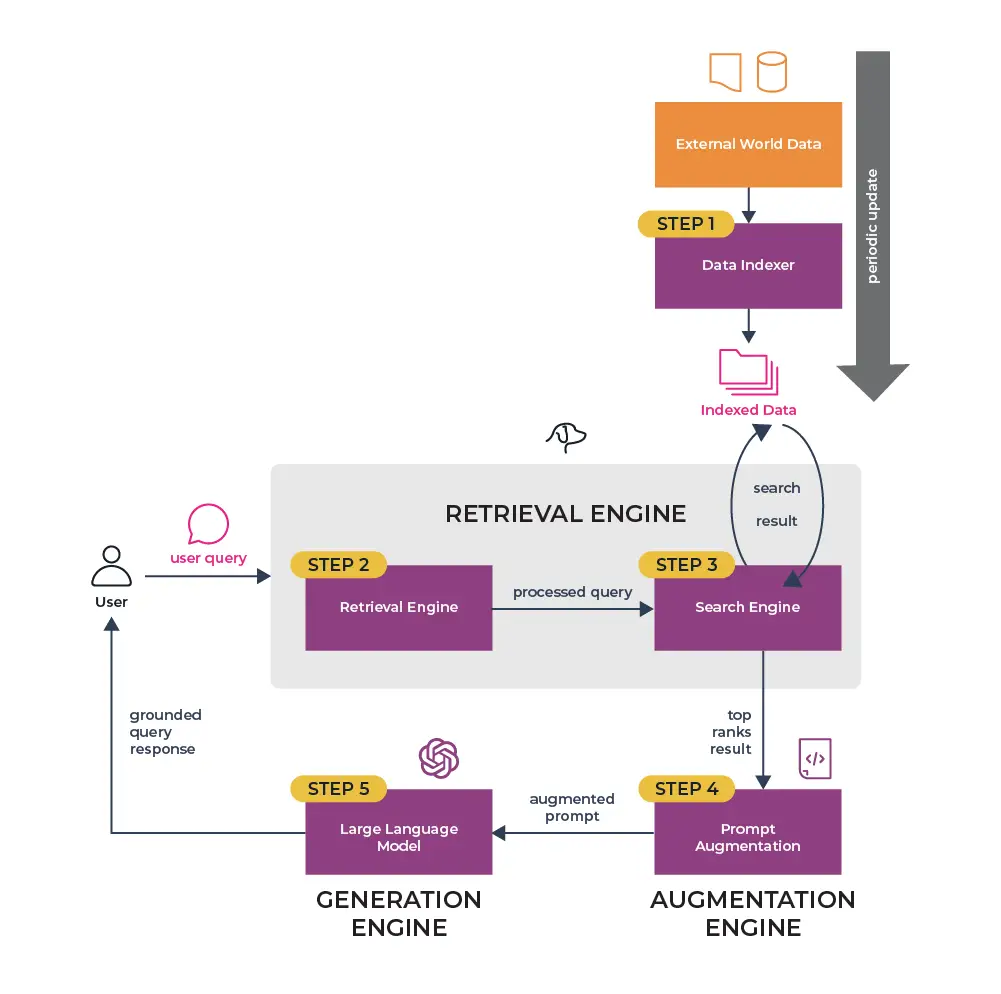
The process involves several steps:
Step 1: Query Processing
When a user provides a query or prompt, the first step is to process and understand the query. This involves techniques like text normalization, tokenization, and named entity recognition to extract the key information and intent from the query.
The query may also undergo expansion or reformulation to improve retrieval performance. This can include techniques like synonym expansion, query rewriting, or adding relevant context. The goal is to transform the query into a format that maximizes the chances of retrieving relevant information from the knowledge corpus.
Step 2: Retrieval
The processed query is passed to the retriever component, which searches the indexed knowledge corpus to find the most relevant passages. The retriever uses the dense vector representation of the query and compares it against the vector representations of the passages in the index.
The comparison is typically done using a similarity search algorithm like Maximum Inner Product Search (MIPS). MIPS finds the passage vectors that have the highest dot product similarity with the query vector, indicating high relevance. The retriever may also employ additional techniques like term-matching, TF-IDF weighting, or inverted indexing to improve the efficiency and accuracy of the retrieval process.
The retriever returns a ranked list of the top-k most relevant passages, where k is a hyperparameter that can be tuned based on the specific application and resource constraints. The retrieved passages are then passed to the next stage of the RAG pipeline.
Step 3: Reranking and Filtering
In some RAG architectures, the retrieved passages undergo a reranking and filtering step to further refine their relevance. This step uses more advanced models, such as cross-attention transformers or BERT-based models, to assess the semantic similarity and information overlap between the query and each retrieved passage.
The reranker assigns relevance scores to the passages based on factors like semantic coherence, information completeness, and query coverage. It may also apply filters to remove duplicates, low-quality passages, or passages that contain irrelevant or harmful content.
The reranked and filtered passages are then selected as the final set of context for the generator. The number of passages used may vary depending on the specific RAG implementation and the complexity of the query.
Step 4: Context Augmentation
The selected passages are combined with the original query to form an augmented context for the generator. This typically involves concatenating the query and passages together, separated by special tokens to indicate their boundaries.
The augmented context allows the generator to attend to both the query and the retrieved information during the generation process. It provides the generator with the necessary background knowledge and relevant details to produce an informed and accurate response.
Step 5: Generation
The augmented context is fed into the generator component, which is typically a large pretrained language model like GPT-3, BERT, or T5. The generator uses its language modeling capabilities to generate a natural language response based on the input context.
The generator attends to both the query and the retrieved passages, using attention mechanisms to identify and incorporate the most relevant information into the generated text. It may also employ techniques like copy mechanisms, content planning, or template-based generation to ensure the coherence and fluency of the response.
The generation process can be controlled using various decoding strategies, such as beam search, top-k sampling, or nucleus sampling. These strategies help balance the quality, diversity, and relevance of the generated responses.
Step 6: Response Postprocessing
After the generator produces the initial response, it may undergo a postprocessing step to refine and improve the output. This can include tasks like grammar correction, entity linking, or sentiment analysis to ensure the response is accurate, appropriate, and aligned with the user’s intent.
The postprocessing step may also involve applying safety checks or content filters to prevent the generation of harmful, biased, or offensive content. This helps maintain the integrity and trustworthiness of the RAG system.
Step 7: User Interaction and Feedback
The final response is returned to the user, who can provide feedback or ask follow-up questions. The user’s feedback can be used to update the RAG system’s knowledge corpus, improve the retrieval and generation models, or refine the response postprocessing steps.
In some RAG implementations, user feedback is incorporated into the retrieval and generation process in real-time. For example, if the user indicates that the generated response is unsatisfactory or incomplete, the RAG system can retrieve additional relevant passages and generate an updated response based on the expanded context.
Throughout the RAG process, the system leverages the strengths of both retrieval and generation approaches. The retriever allows access to vast amounts of external knowledge, while the generator provides the language understanding and generation capabilities to produce coherent and informative responses.
Through iteratively retrieving, reranking, and integrating relevant information from the knowledge corpus, RAG enables the generation of accurate, up-to-date, and contextually appropriate responses to a wide range of queries. The specific implementation details and architectures may vary across RAG systems, but this general process forms the core of the retrieval augmented generation approach.
What Are the Technological Foundations of RAG?
1. Large Language Models:
At the core of RAG systems are large pretrained language models, such as GPT-3, BERT, or T5. These models have been trained on vast amounts of text data using self-supervised learning techniques, allowing them to capture rich linguistic knowledge and generate human-like text.
The language models used in RAG are typically transformer-based architectures, which have shown remarkable performance in various natural language processing tasks. They are pretrained on large-scale corpora like web pages, books, or articles, learning to predict the next word or masked words in a sequence.
The pretraining process allows the language models to learn general language understanding and generation capabilities. They can then be fine-tuned on specific tasks, such as question answering or dialogue generation, with relatively small amounts of task-specific data.
In RAG, the pretrained language models serve as the generator component, taking the augmented context (query + retrieved passages) as input and generating the final response. The models’ ability to attend to and incorporate information from the retrieved passages is crucial for producing informed and relevant responses.
2. Dense Vector Embeddings:
RAG relies on dense vector representations of text to enable efficient and effective retrieval from large knowledge corpora. Dense vector embeddings, also known as continuous representations or distributed representations, map text into fixed-length vectors in a high-dimensional space.
The dense vector embeddings capture the semantic meaning and relationships between words, phrases, or passages. They are typically obtained using neural encoding models, such as Word2Vec, GloVe, or BERT, which learn to represent text based on its context and co-occurrence patterns.
In RAG, both the queries and the passages in the knowledge corpus are encoded into dense vector representations. This allows for efficient similarity search and retrieval, as the vector representations can be compared using mathematical operations like dot product or cosine similarity.
The quality of the dense vector embeddings is crucial for the retrieval performance of RAG. Well-trained embeddings should capture the semantic similarity between related concepts and enable the retrieval of relevant passages even when there is no exact term overlap with the query.
3. Similarity Search:
Efficient similarity search is a key technological foundation of RAG, enabling the retrieval of relevant passages from large knowledge corpora in real-time. The most commonly used similarity search technique in RAG is Maximum Inner Product Search (MIPS).
MIPS is an optimization problem that aims to find the passage vectors that have the highest dot product similarity with the query vector. It leverages the properties of inner product computation to efficiently search through a large index of passage vectors and identify the top-k most similar ones.
To enable fast MIPS, the passage vectors are typically organized in specialized data structures like HNSW (Hierarchical Navigable Small World) graphs or IVF (Inverted File) indexes. These data structures allow for efficient nearest neighbor search by partitioning the vector space and using graph traversal or inverted indexing techniques.
The similarity search process in RAG involves encoding the query into a dense vector representation and then performing MIPS against the indexed passage vectors. The top-k most similar passages are retrieved and used as the context for the generator.
Advances in similarity search techniques, such as quantization, pruning, or distributed search, have greatly improved the efficiency and scalability of RAG systems, allowing them to handle large-scale knowledge corpora and real-time retrieval requirements.
4. Knowledge Distillation and Transfer Learning:
RAG systems often employ knowledge distillation and transfer learning techniques to improve the efficiency and effectiveness of the retrieval and generation components.
Knowledge distillation is a technique where a smaller, more compact model (student) is trained to mimic the behavior of a larger, more complex model (teacher). In RAG, knowledge distillation can be used to compress the large pretrained language models used as generators into smaller, more efficient models that retain most of the knowledge and generation capabilities.
Transfer learning involves leveraging the knowledge learned from one task or domain to improve performance on another related task or domain. In RAG, transfer learning is commonly used to adapt the pretrained language models to specific domains or tasks.
For example, a language model pretrained on general web text can be fine-tuned on a domain-specific corpus, such as medical literature or legal documents, to improve its performance on domain-specific queries. Transfer learning allows RAG systems to benefit from the general language understanding capabilities of pretrained models while specializing them for specific use cases.
5. Attention Mechanisms and Transformers:
Attention mechanisms and transformer architectures are fundamental to the functioning of RAG systems. Attention allows the models to selectively focus on different parts of the input sequence and capture long-range dependencies.
In the retriever component, attention mechanisms are used to compute the similarity between the query and passage representations. This allows the retriever to identify the most relevant passages based on their semantic similarity to the query.
In the generator component, transformers with self-attention and cross-attention mechanisms are used to process the augmented context (query + retrieved passages). Self-attention allows the model to attend to different parts of the input sequence and capture the relationships between them. Cross-attention enables the model to attend to the retrieved passages and incorporate relevant information into the generated response.
The transformer architecture, with its multi-head attention and feedforward layers, has proven to be highly effective in language understanding and generation tasks. It allows RAG systems to effectively process and integrate information from multiple sources (query and retrieved passages) to produce coherent and informative responses.
6. Neural Information Retrieval:
Neural information retrieval (neural IR) techniques are increasingly being used in RAG systems to improve the retrieval performance. Neural IR involves using deep learning models to learn complex relevance patterns and match queries with relevant documents.
In RAG, neural IR techniques can be used to enhance the retriever component by learning to rank passages based on their relevance to the query. This can involve using models like BERT or other transformer-based architectures to compute the relevance scores between the query and passage representations.
Neural IR models can be trained using supervised learning on labeled query-passage pairs, where the labels indicate the relevance of each passage to the corresponding query. The models learn to capture the semantic matching patterns and rank the passages based on their relevance scores.
By incorporating neural IR techniques, RAG systems can improve the quality and relevance of the retrieved passages, leading to more accurate and informative generated responses.
These technological foundations, including large language models, dense vector embeddings, similarity search, knowledge distillation, transfer learning, attention mechanisms, transformers, and neural information retrieval, collectively enable the effective functioning of retrieval augmented generation systems. As these technologies continue to advance, RAG systems are expected to become even more powerful and capable of handling complex information retrieval and generation tasks.
Pros and Cons of Using RAG
Pros:
- Improved accuracy and informativeness of generated text by grounding the language model in retrieved external knowledge
- Ability to access up-to-date information without expensive model retraining
- Reduced hallucination and inconsistency issues compared to standard language models
- Efficient approach to building knowledge-intensive applications by reusing pretrained language models
- Flexibility to use custom knowledge sources for domain-specific applications
Cons:
- Retrieval errors can lead to irrelevant or incorrect information being used by the generator
- Generating coherent and fluent responses that integrate retrieved information is challenging
- Retrieving appropriate passages for complex queries that require reasoning over multiple pieces of information is difficult
- Performance is dependent on the quality and coverage of the knowledge corpus
- Lack of direct interpretability and control over the generated outputs
- Potential for biased or unsafe content if the knowledge corpus contains such information
What Are the Applications of RAG?
RAG has been successfully applied to a variety of natural language processing tasks and applications.
Question Answering:
RAG can be used to build systems that answer questions by retrieving relevant information from a knowledge base and generating natural language responses. This includes both open-domain QA over large web corpora and closed-domain QA over specific knowledge bases.
Conversational AI & Chatbots:
RAG enables building dialogue systems and chatbots that can engage in informative conversations by leveraging external knowledge. This allows chatbots to answer a wide range of user queries and provide in-depth information on various topics.
Knowledge Base Querying:
RAG provides a natural language interface for querying structured and unstructured knowledge bases. Users can ask questions in plain language and RAG will retrieve and generate responses based on the stored knowledge.
Information Retrieval & Summarization:
RAG can be applied to retrieve and summarize relevant information for a given topic or query. By generating summaries that integrate information from multiple retrieved passages, RAG helps users quickly get the key points without needing to read through long documents.
Fact Checking & Claim Verification:
RAG can be used to assess the veracity of claims by retrieving relevant evidence from trusted information sources. The generated responses can provide substantiating or refuting information to help determine the truthfulness of a claim.
Content Generation:
RAG can assist with generating informative and factual content by leveraging external knowledge sources. This includes applications like generating product descriptions, writing educational content, or creating data sheets based on technical specifications.
Retrieval augmented generation is an impactful AI technology that combines the strengths of retrieval and generative language modeling. As RAG continues to advance, it will unlock new possibilities for knowledge-driven AI applications across domains.