This page compiles assessments and evaluations of Claude models, The benchmarks measure Claude models’ capabilities as a language model across diverse NLP tasks including textual entailment, question answering, summarization, and dialogue. I hope this page can give you a comprehensive overview of Claude models’ language proficiencies and how they compare to other state-of-the-art AI systems.
Benchmarks & Reviews
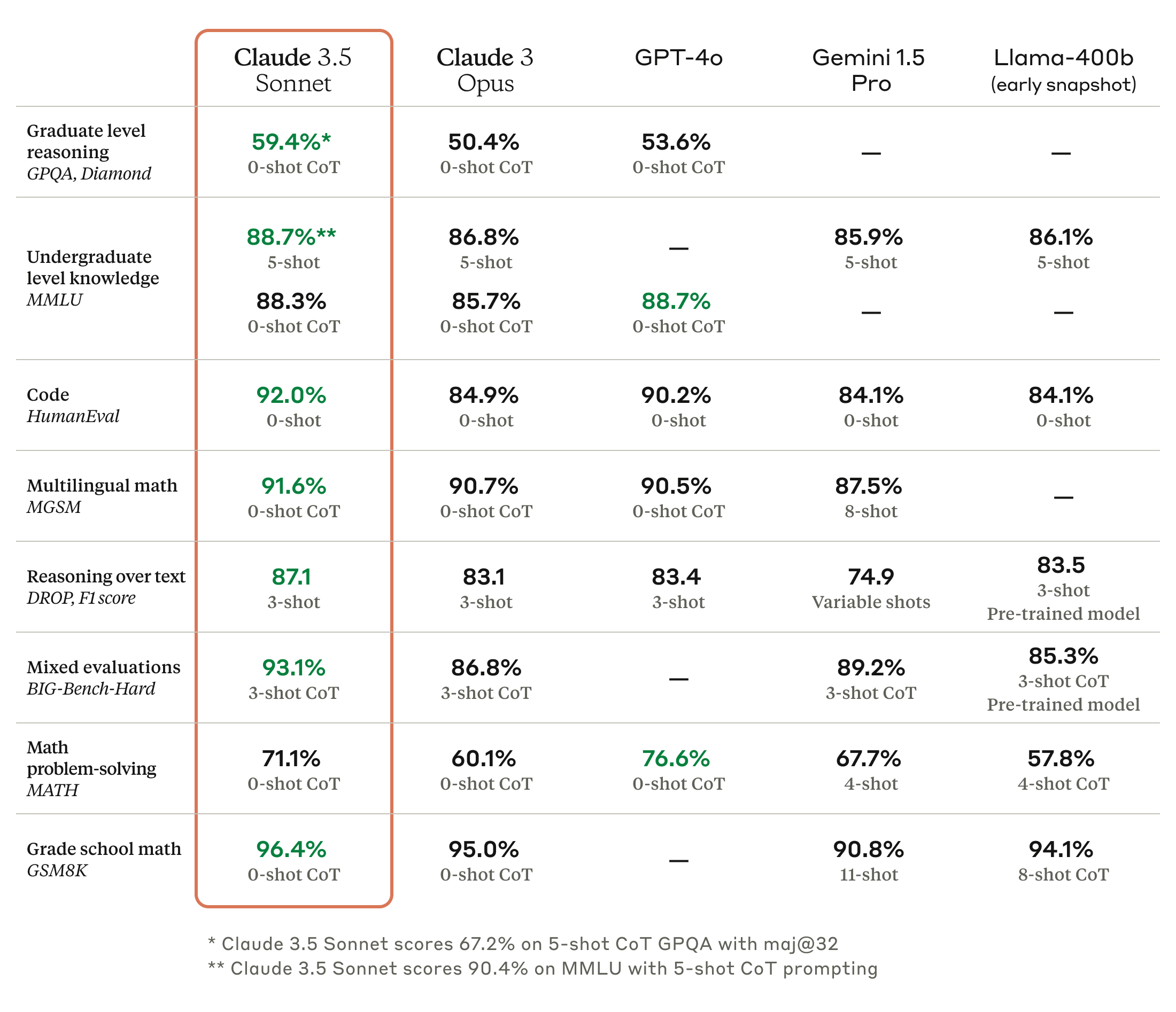
Here are the scores of Claude 3.5 Sonnet:
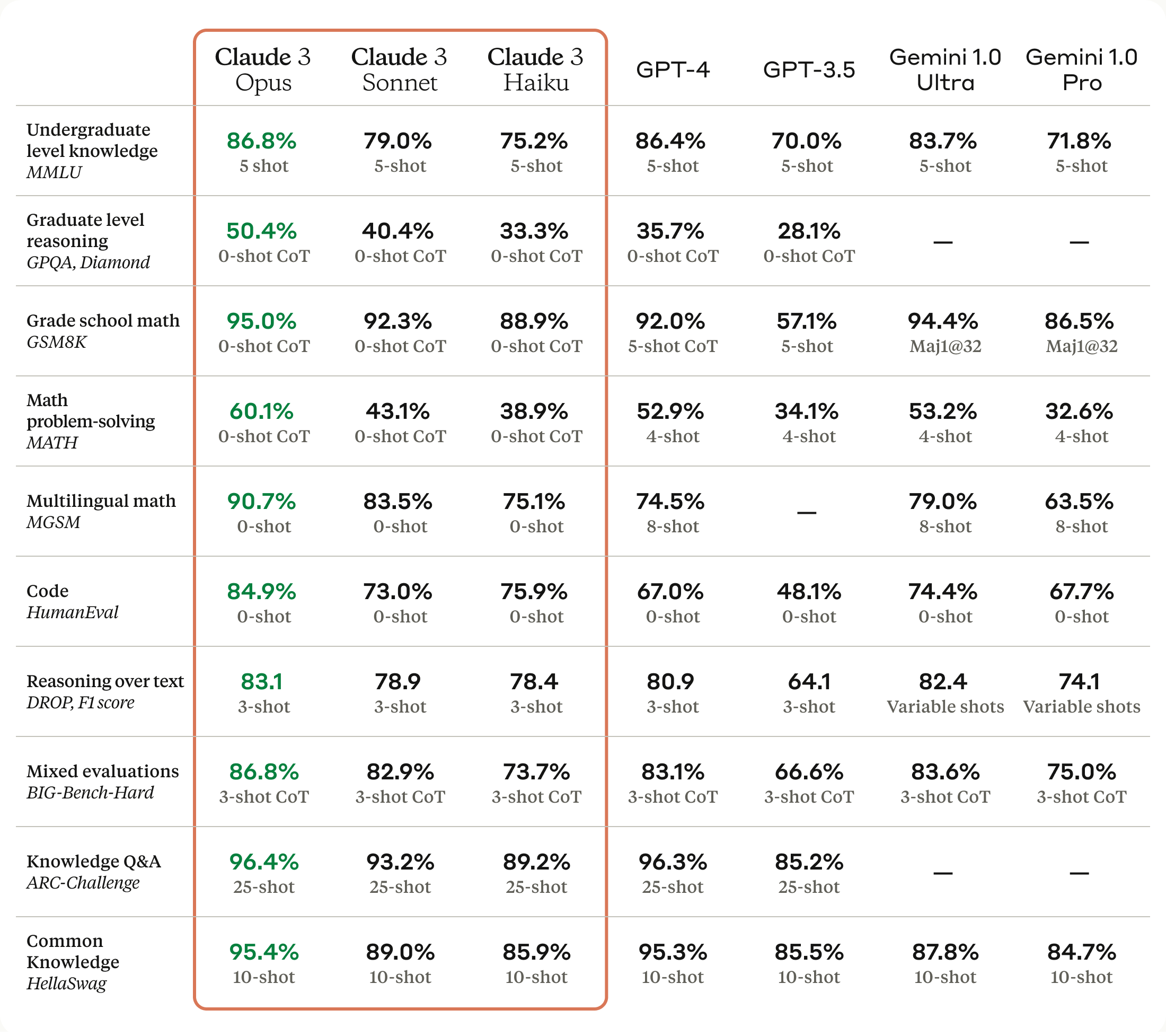
Here are the scores of Claude 3 Models:
Here are the scores of Claude 2 in all the popular tests:
- 76.5% (Claude 2 score on Bar exam multiple choice)
- 73.0% (Claude 1.3 score on Bar exam multiple choice)
- 90th percentile (Claude 2 GRE reading/writing score compared to grad school applicants)
- median (Claude 2 GRE quantitative reasoning score compared to grad school applicants)
- 71.2% (Claude 2 score on Codex HumanEval)
- 56.0% (Previous Claude score on Codex HumanEval)
- 88.0% (Claude 2 score on GSM8k math problems)
- 85.2% (Previous Claude score on GSM8k math problems)
- 2x better (Claude 2 vs Claude 1.3 at giving harmless responses)
Reviews from various sources:
- How Good is the Claude 2 AI at Working With PDFs? – Let’s Find Out – page
- Model Card and Evaluations for Claude Models – PDF
- Claude 3.5 Sonnet Model Card Addendum – PDF
- Claude 3 Model Card – PDF
- ARB: Advanced Reasoning Benchmark for Large Language Models – PDF
- LLM hallucinations graded – Google Sheet
- Llama 2 vs Claude 2 vs GPT-4 – video
- After using Claude 2 by Anthropic for 12 hours straight, here’s what I found – Reddit Discussion
- How strong is Claude 2? – video
- What to Know About Claude 2, Anthropic’s Rival to ChatGPT – page
Got a question or a recommendation? Please send me a message at [email protected].