
What Is a Small Language Model?
A small language model (SLM) is a type of artificial intelligence model designed to process and generate human language, but with a significantly smaller number of parameters compared to large language models (LLMs). While LLMs can have hundreds of billions of parameters, SLMs typically have a few billion parameters or less.
The term “small” in SLM refers to several aspects of the model:
- Number of parameters: SLMs have fewer parameters than LLMs, often in the range of millions to a few billion. Parameters are the learnable variables in a neural network that capture patterns and relationships in the training data.
- Model size: Due to the reduced number of parameters, SLMs have a smaller model size in terms of memory footprint and storage requirements. This makes them more efficient to store, load, and run on various devices.
- Computational requirements: SLMs require less computational power and resources to train and run compared to LLMs. They can be trained and deployed on smaller-scale hardware, making them more accessible and cost-effective.
- Training data: SLMs are often trained on smaller, more focused datasets compared to the vast and diverse datasets used for training LLMs. This allows SLMs to specialize in specific domains or tasks.
Despite their smaller size, SLMs can still achieve impressive performance on various natural language processing tasks, such as text classification, sentiment analysis, named entity recognition, and language generation. They use advanced techniques like transfer learning, fine-tuning, and knowledge distillation to learn from pre-trained larger models and adapt to specific tasks with less data.
Some examples of small language models include DistilBERT, TinyBERT, MobileBERT, and Phi-2. These models have been designed to maintain a good balance between performance and efficiency while being more lightweight than their larger counterparts.
What Is Phi-3?
Phi-3 is a family of small language models (SLMs) developed by Microsoft. These models are designed to deliver impressive performance while remaining compact and cost-effective. The Phi-3 family includes three models:
- Phi-3-mini: A 3.8 billion parameter language model
- Phi-3-small: A 7 billion parameter language model (coming soon)
- Phi-3-medium: A 14 billion parameter language model (coming soon)
Phi-3 models are open AI models, meaning their weights and architectures are publicly available. They are trained using high-quality data and advanced techniques like reinforcement learning from human feedback (RLHF). The goal of Phi-3 is to provide developers with powerful yet practical models that can be deployed in resource-constrained environments.
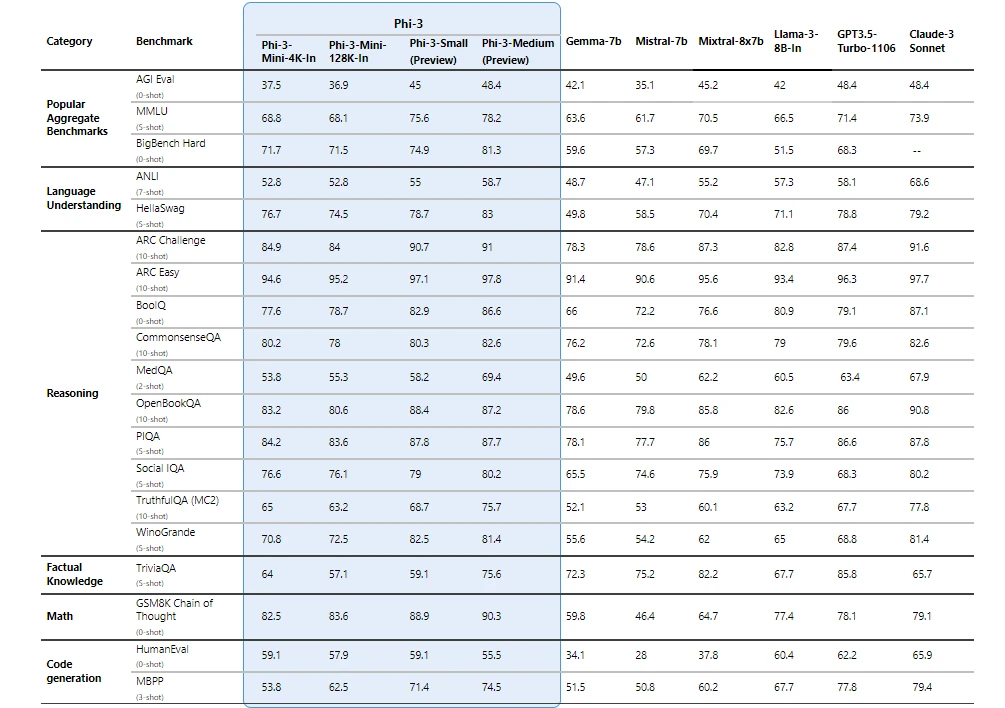
Microsoft claims that Phi-3 models significantly outperform other models of the same size and even larger models on key benchmarks related to language understanding, reasoning, coding, and math.
What Are the Technical Specifications of the Phi-3 Models?
The flagship model of the Phi-3 family, Phi-3-mini, comes with the following specifications:
- Model size: 3.8 billion parameters
- Context window: Available in 4K and 128K token variants. Phi-3-mini is the first model in its class to support up to 128K tokens.
- Instruction-tuned: The model is pre-trained to follow various instructions, making it ready to use out-of-the-box.
- Optimized for ONNX Runtime: Supports Windows DirectML and offers cross-platform compatibility with GPU, CPU, and mobile hardware.
- Available as NVIDIA NIM microservice: Can be deployed anywhere using a standard API interface. Optimized for NVIDIA GPUs.
Phi-3-small and Phi-3-medium, with 7 billion and 14 billion parameters respectively, will be released in the coming weeks. These models will provide more options across the quality-cost curve.
All Phi-3 models are developed in accordance with Microsoft’s Responsible AI Standard. They undergo rigorous safety evaluations, red-teaming, sensitive use reviews, and adhere to security best practices. The models are further refined using techniques like RLHF and automated testing across various harm categories.
What Are the Main Differences Between Claude 3 & Phi-3?
Model size and architecture
- Claude 3 models are large language models (LLMs) with parameter counts ranging from 70 billion (Claude 3 Haiku) to over 100 billion (Claude 3 Opus). They use a transformer architecture.
- Phi-3 models are small language models (SLMs) with parameter counts ranging from 3.8 billion (Phi-3-mini) to 14 billion (Phi-3-medium). They also use a transformer architecture but are designed for efficiency.
Training data and approach
- Claude 3 models are trained on a vast corpus of web data using constitutional AI principles to align them with human values. They employ techniques like RLHF and AI safety via debate.
- Phi-3 models are trained on carefully curated, high-quality datasets including synthetic data generated by larger models. They also use RLHF and undergo extensive safety evaluations.
Performance and benchmarks
- Claude 3 models excel at a wide range of tasks including language understanding, reasoning, coding, creative writing, and open-ended conversation. They have achieved state-of-the-art results on benchmarks like MMLU and HumanEval.
- Phi-3 models punch above their weight, outperforming larger models on specific benchmarks related to language, reasoning, coding and math. However, they may lag behind on factual knowledge retention due to their smaller size.
Deployment and use cases
- Claude 3 models are primarily designed for cloud deployment and can power applications like chatbots, content generators, and coding assistants that require deep language understanding and generation capabilities.
- Phi-3 models are optimized for efficient inference in resource-constrained environments such as on-device, offline, and edge scenarios. They are well-suited for applications with latency, cost, or connectivity constraints.
Availability and ecosystem
- Claude 3 models are available through Anthropic’s API and have integrations with platforms like Slack and Notion. Anthropic provides a dedicated Constitutional AI model to help developers build safe and ethical applications.
- Phi-3 models are open and available through Azure AI Studio, Hugging Face, and Ollama. They can be easily fine-tuned and integrated into applications using Azure’s AI development tools and services.
The following table provides a side-by-side comparison of the two model families:
| Aspect | Phi-3 | Claude 3 |
|---|---|---|
| Model Size | Small (3.8B to 14B parameters) | Large (70B+ parameters) |
| Performance | Outperforms larger models on specific tasks | Excels at a wide range of language tasks |
| Efficiency | High performance relative to size | Requires significant computational resources |
| Deployment | Flexible, suitable for on-device, offline, and edge scenarios | Primarily designed for cloud deployment |
| Cost | More affordable due to lower computational requirements | Higher cost due to computational demands |
| Fine-tuning | Easier and faster to fine-tune for specific tasks | Fine-tuning can be more resource-intensive |
| Knowledge | Limited factual knowledge retention due to smaller size | Extensive knowledge base spanning various domains |
| Context | Supports context windows up to 128K tokens | Can maintain coherence over long passages or conversations |
| Creativity & Analysis | Excels at specific tasks like reasoning and math | Demonstrates strong creative and analytical abilities |
| Safety & Ethics | Developed with strict AI ethics and safety standards | Aligned with human values using constitutional AI principles |
| Ecosystem | Growing ecosystem and developer support | More established ecosystem and developer resources |
Both Claude 3 and Phi-3 represent significant advancements in LLMs, they cater to different use cases and deployment scenarios.
Claude 3’s strength lies in its deep language understanding and generation capabilities, making it ideal for complex, open-ended applications. Phi-3, on the other hand, excels at providing efficient and cost-effective language modeling for resource-constrained environments and applications with specific performance requirements.
What Are the Strengths and Weaknesses of Phi-3 Against Claude 3?
Strengths of Phi-3 against Claude 3:
- Efficiency: One of the advantages of Phi-3 models is their ability to deliver impressive performance while being much smaller than Claude 3. This efficiency allows Phi-3 to outperform Claude 3 on specific tasks while consuming significantly fewer computational resources.
- Deployment flexibility: Phi-3’s compact size and optimizations make it more versatile in terms of deployment options. Unlike Claude 3, which is primarily designed for cloud deployment, Phi-3 can be effectively used in on-device, offline, and edge scenarios. This flexibility opens up new possibilities for AI applications in resource-constrained environments.
- Cost-effectiveness: Running large language models like Claude 3 can be expensive due to their substantial computational requirements. In contrast, Phi-3 models are more cost-effective, as they can achieve comparable performance on certain tasks while consuming fewer resources. This makes Phi-3 an attractive choice for applications with budget constraints.
- Ease of fine-tuning: Fine-tuning a language model for specific tasks or domains can be time-consuming and resource-intensive, especially for large models like Claude 3. Phi-3’s smaller size makes the fine-tuning process faster and more manageable, allowing developers to quickly adapt the model to their specific needs.
- Safety and responsibility: Both Phi-3 and Claude 3 are developed with a focus on AI ethics and safety. However, Phi-3 models undergo particularly rigorous testing and evaluation to mitigate potential risks and harms. This emphasis on responsible AI development is a notable strength of Phi-3.

Weaknesses of Phi-3 against Claude 3:
- Limited factual knowledge: Due to their smaller size, Phi-3 models have a lower capacity for storing and recalling factual information compared to Claude 3. This limitation can be a disadvantage in applications that require a broad knowledge base spanning various domains.
- Narrow scope: While Phi-3 models excel at specific tasks, they may lack the breadth of capabilities demonstrated by more general-purpose models like Claude 3. For applications that require versatility and the ability to handle a wide range of tasks, Claude 3 may be the better choice.
- Lack of long-term memory: Phi-3 models, even with the 128K token context window, have a more limited ability to maintain long-term coherence and context compared to Claude 3. This weakness can impact Phi-3’s performance on tasks that involve processing long documents or engaging in extended conversations.
- Potential biases: Like all language models, Phi-3 may exhibit biases or limitations based on its training data. While efforts are made to use high-quality data and mitigate biases, it’s important to be aware of this potential weakness, especially when compared to Claude 3, which has been developed using constitutional AI principles to align with human values.
- Ecosystem maturity: As a newer entrant in the language model landscape, Phi-3’s ecosystem and developer support may not be as extensive as Claude 3’s. This relative lack of maturity could impact the availability of resources, tools, and community support for developers working with Phi-3.
Which Model Is Better?
Having examined the strengths and weaknesses of both Phi-3 and Claude 3, it’s clear that there is no one-size-fits-all answer to which model is “better.” The choice ultimately depends on the specific needs and constraints of the application or use case at hand. However, I’ll share my personal opinion based on the information available.
For applications where efficiency, cost-effectiveness, and deployment flexibility are the top priorities, Phi-3 has a clear edge. Its ability to deliver impressive performance in a small package makes it an attractive choice for scenarios like on-device inference, edge computing, or applications with tight latency requirements. The fact that Phi-3 can run on a wide range of hardware, from mobile devices to cloud instances, opens up new possibilities for AI-powered features and services.
On the other hand, if the application demands deep language understanding, broad knowledge coverage, and open-ended generation capabilities, Claude 3 is the stronger contender. Its large-scale training and constitutional AI principles enable it to handle complex tasks with remarkable coherence and contextual awareness. For applications like content creation, analysis, or open-ended dialogue, Claude 3’s strengths are hard to match.
That said, I believe Phi-3 represents an exciting development in the field of language modeling. The ability to achieve near-par performance with much larger models using a fraction of the resources is a game-changer. It challenges the prevailing wisdom that bigger is always better and opens up new frontiers for efficient and accessible AI.
As AI systems become more pervasive, we need models that are not only capable but also ethical and trustworthy. Microsoft’s commitment to these principles in the development of Phi-3 sets a positive example for the industry.
I expect to see a growing ecosystem of applications and services powered by Phi-3, especially in domains where efficiency and flexibility are paramount. As more developers experiment with and fine-tune these models for specific tasks, we’re likely to discover new use cases and unlock value in previously untapped areas.
At the same time, I believe Claude 3 and other large language models will continue to push the boundaries of what’s possible with AI. As they become more capable, aligned, and accessible, they’ll enable a new generation of intelligent applications that can understand, reason, and communicate like never before.