
What is Prompt Caching in Claude AI?
Prompt caching is a powerful feature in the Claude AI system that allows developers to cache frequently used context between API calls. By caching prompts, developers can provide Claude with more background knowledge and example outputs, leading to improved performance and reduced costs. This feature was announced by Anthropic on August 15, 2024, and became available for all Anthropic API users in public beta on that date.
When you send a prompt to Claude, the model processes the prompt and generates a response. With prompt caching, you can store the prompt and its associated context in a cache, so that subsequent requests can reuse this cached information. This reduces the amount of data that needs to be sent with each request, resulting in lower latency and reduced costs.
Main Benefits of Using Prompt Caching
- Reduced Latency: By reusing cached prompts, Claude can generate responses more quickly, reducing the time to first token by up to 85% for long prompts.
- Cost Savings: Prompt caching can reduce costs by up to 90% for long prompts, as the cached content is significantly cheaper to use compared to sending the full prompt with each request.
- Improved Performance: With more background knowledge and example outputs available in the prompt, Claude can generate higher-quality responses that better match the user’s intent.
- Easier Integration: Prompt caching simplifies the integration process, as developers can send a large amount of prompt context once and then refer to that information repeatedly in subsequent requests.
What is the Potential Latency Reduction with Prompt Caching?
The potential latency reduction with prompt caching is significant and varies depending on the size and complexity of the prompt being used. With cached prompts, developers can streamline interactions with Claude, resulting in faster response times across various applications.
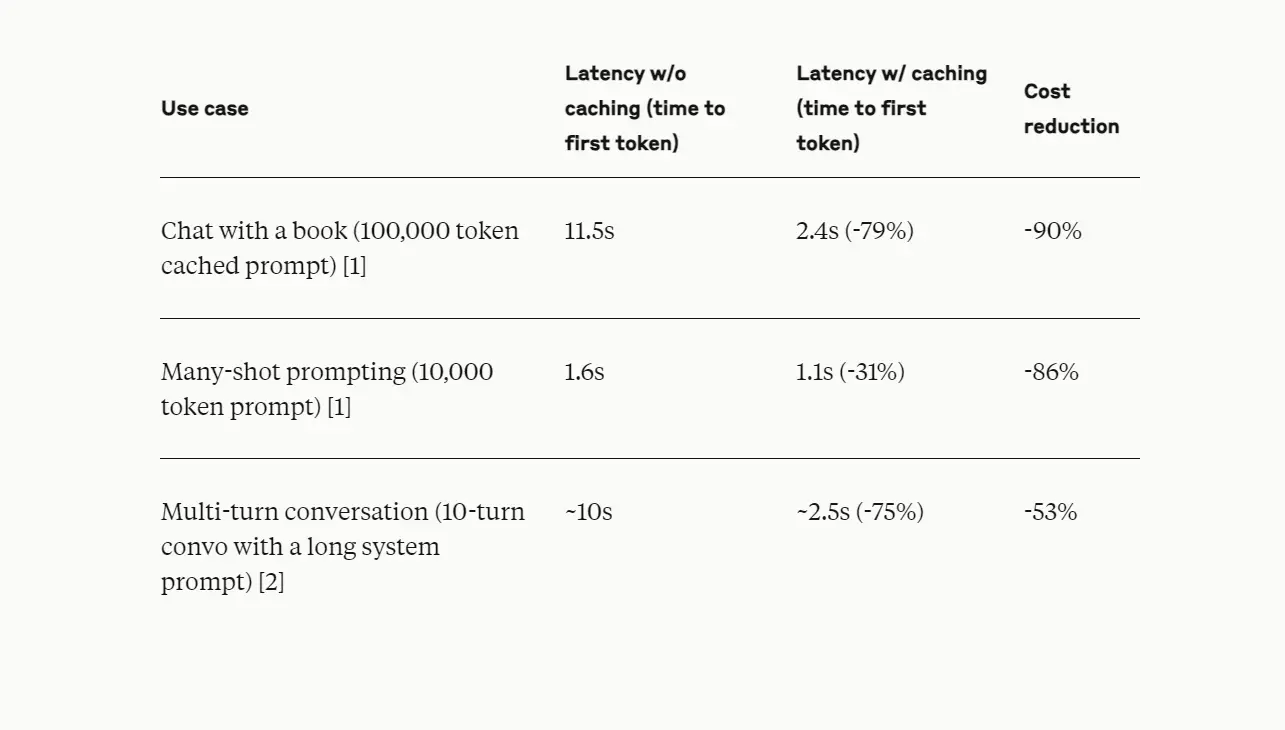
Latency Reduction Metrics
- Chat with a Book: For instances where users engage with a large text, such as a book, the latency reduction is particularly pronounced. In one case, using a 100,000 token cached prompt (e.g., chatting with a book), the latency decreased from 11.5 seconds to just 2.4 seconds, representing a remarkable 79% reduction. This significant drop allows users to interact with lengthy texts without enduring long wait times.
- Many-shot Prompting: In scenarios where developers use many-shot prompting—providing Claude with numerous examples to guide its responses—latency also sees a considerable decrease. For a 10,000 token prompt, latency reduced from 1.6 seconds to 1.1 seconds, a 31% decrease. This improvement means that developers can provide extensive examples without sacrificing speed.
- Multi-turn Conversations: For applications involving multi-turn conversations, where users engage in back-and-forth dialogue with Claude, prompt caching proves invaluable. In a test involving a 10-turn conversation with a long system prompt, latency dropped from approximately 10 seconds to around 2.5 seconds, achieving a 75% reduction. This enhancement is crucial for conversational agents that require quick, responsive interactions.
Factors Influencing Latency Reduction
Several factors influence the degree of latency reduction that can be achieved through prompt caching:
- Prompt Size: Larger prompts tend to benefit more from caching. The more data that can be cached and reused, the greater the potential reduction in latency.
- Complexity of Requests: Complex requests that require extensive context or background information can see more significant latency improvements when using cached prompts.
- Frequency of Use: The more frequently a particular prompt or context is used, the more beneficial caching becomes. Repeatedly accessing cached data minimizes the need for Claude to reprocess the same information.
Implications for Developers
For developers, the implications of reduced latency are profound. Faster response times enhance user experience, making applications powered by Claude more efficient and engaging. Whether building conversational agents, coding assistants, or tools for processing large documents, prompt caching allows developers to deliver high-quality interactions without the burden of long wait times.
How Does Prompt Caching Work with Claude Models?
Prompt caching in Claude models is designed to optimize the interaction between developers and the AI by storing and reusing frequently accessed prompt contexts. This capability streamlines the process of sending requests to Claude, allowing for faster responses and reduced costs.
Architecture of Prompt Caching
The architecture of prompt caching is built around the concept of maintaining a cache that holds previously used prompts and their associated contexts. This cache is designed to be efficiently accessed by Claude during API calls, allowing the model to retrieve relevant information without needing to reprocess large amounts of data.
- Cache Storage: The cached prompts are stored in a temporary memory space that Claude can access quickly. This storage can handle a significant amount of data, accommodating the large context windows of Claude models, which can reach up to 200,000 tokens.
- Cache Retrieval: When a new request is made, Claude first checks the cache for any previously stored prompts that match the current request. If a match is found, Claude retrieves the cached context, significantly speeding up the response generation process.
The Caching Mechanism
The caching mechanism operates through a series of steps that ensure efficient storage and retrieval of prompts:
- Prompt Submission: When developers submit a prompt to Claude, they can include a unique prompt cache ID. This ID serves as an identifier for the cached prompt, allowing Claude to recognize and reuse it in future requests.
- Cache Writing: If the prompt is new or has been modified, Claude writes the prompt and its context to the cache. Writing to the cache incurs a cost, which is higher than the base input token price. For example, writing to the cache for Claude 3.5 Sonnet costs $3.75 per million tokens.
- Cache Reading: When a subsequent request is made that matches a cached prompt, Claude reads from the cache. This process is significantly cheaper, costing only $0.30 per million tokens for Claude 3.5 Sonnet. This cost structure incentivizes developers to leverage caching for frequently used prompts.
- Cache Management: The caching system is designed to manage the stored prompts effectively. It can handle the addition of new prompts while maintaining the integrity and accessibility of existing cached data. Developers can also clear or update cached prompts as needed.
Which Claude Models Support Prompt Caching?
Prompt caching is an innovative feature that enhances the performance of Claude models by allowing developers to store and reuse frequently accessed prompts. Currently, prompt caching is available for the following Claude models:
- Claude 3.5 Sonnet
- Claude 3 Opus
- Claude 3 Haiku
These models are designed to handle complex tasks and large datasets, making them ideal candidates for leveraging prompt caching effectively.
What is the Cost of Writing to the Cache and Reading from the Cache for Claude 3.5 Sonnet?
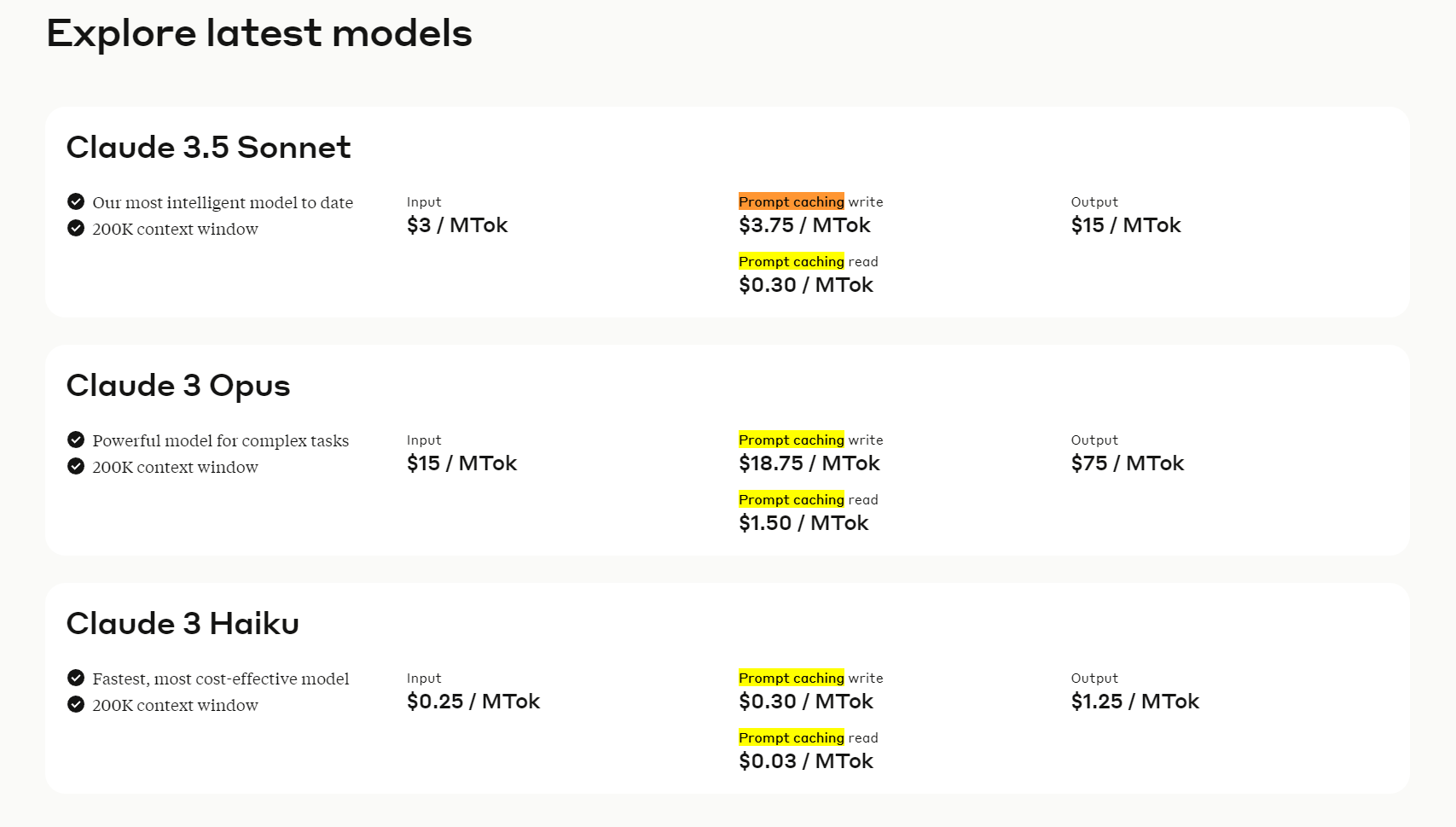
Claude 3.5 Sonnet
- Description: Claude 3.5 Sonnet is the most intelligent model in the Claude series, optimized for nuanced understanding and generation of text. It excels in tasks requiring deep contextual awareness and creativity.
- Context Window: 200,000 tokens, allowing for the caching of extensive prompt contexts.
- Cost Structure:
- Input Cost: $3 per million tokens (MTok)
- Cache Write Cost: $3.75 per MTok
- Cache Read Cost: $0.30 per MTok
- Output Cost: $15 per MTok
Claude 3 Opus
- Description: Claude 3 Opus is a powerful model designed for complex tasks that require analytical reasoning and detailed responses. It is particularly effective in scenarios involving intricate problem-solving and multi-step reasoning.
- Context Window: 200,000 tokens, enabling the handling of large and detailed prompts.
- Cost Structure:
- Input Cost: $15 per MTok
- Cache Write Cost: $18.75 per MTok
- Cache Read Cost: $1.50 per MTok
- Output Cost: $75 per MTok
Claude 3 Haiku
- Description: Claude 3 Haiku is the fastest and most cost-effective model in the Claude lineup, optimized for rapid responses and efficiency. It is ideal for applications requiring quick interactions and straightforward queries.
- Context Window: 200,000 tokens, allowing for efficient caching of prompts.
- Cost Structure:
- Input Cost: $0.25 per MTok
- Cache Write Cost: $0.30 per MTok
- Cache Read Cost: $0.03 per MTok
- Output Cost: $1.25 per MTok
Is Prompt Caching Available for All Anthropic API Users?
Yes, prompt caching is available for all Anthropic API users in public beta. To start using prompt caching, you can explore the documentation and pricing page on the Anthropic website.
Will prompt caching become be available for future cloud models (Claude 3,.5/4/etc.)?
Prompt caching is currently available for Claude 3.5 Sonnet, Claude 3 Opus, and Claude 3 Haiku, but Anthropic has not made any official announcements regarding its availability for future Claude models. However, given the significant benefits of prompt caching in terms of cost reduction and improved latency, it is reasonable to expect that this feature will likely be extended to future iterations of Claude models.
As Anthropic continues to develop and refine its AI technologies, prompt caching may become a standard feature across their model lineup. The success and adoption of this feature in the current models will likely influence its implementation in future versions, such as potential Claude 3.5 or Claude 4 models.
Developers and users should stay tuned to Anthropic’s official announcements and documentation for updates on prompt caching availability in upcoming Claude models. Given the competitive nature of the AI industry and the clear advantages of prompt caching, it would be surprising if Anthropic didn’t continue to offer and potentially expand this feature in future releases.
In What Situations is Prompt Caching Most Effective?
Prompt caching can be effective in various situations where you want to send a large amount of prompt context once and then refer to that information repeatedly in subsequent requests. Some examples include:
- Conversational agents: Reduce cost and latency for extended conversations, especially those with long instructions or uploaded documents.
- Coding assistants: Improve autocomplete and codebase Q&A by keeping a summarized version of the codebase in the prompt.
- Large document processing: Incorporate complete long-form material, including images, in your prompt without increasing response latency.
- Detailed instruction sets: Share extensive lists of instructions, procedures, and examples to fine-tune Claude’s responses.
- Agentic search and tool use: Enhance performance for scenarios involving multiple rounds of tool calls and iterative changes, where each step typically requires a new API call.
- Talking to books, papers, documentation, podcast transcripts, and other long-form content: Bring any knowledge base alive by embedding the entire document(s) into the prompt, and letting users ask it questions.
Can Prompt Caching Be Used with Image Inputs?
Yes, prompt caching can be used with image inputs in Claude models. However, there are some important considerations to keep in mind:
- Images can be included in the cached portion of prompts, allowing for efficient reuse of visual content across multiple API calls.
- The presence or absence of images in a prompt affects caching. Adding or removing images anywhere in the prompt will invalidate the cache, requiring a new cache entry to be created.
- For optimal performance, it’s recommended to include images in the cacheable portion of the prompt when they are part of the stable, reusable content.
- When using prompt caching with images, ensure that the image content remains consistent across calls to maintain cache validity.
Leveraging prompt caching with image inputs allows developers to incorporate visual elements into their prompts while maintaining the performance benefits of caching. This approach is particularly effective when working with large documents or datasets that include both text and images. Developers can efficiently reuse visual content across multiple API calls, optimizing performance and reducing costs.
How Does Prompt Caching Help with Large Document Processing?
Prompt caching is particularly useful for processing large documents, as it allows you to incorporate the entire document into the prompt without significantly increasing response latency or costs.Here’s how you can use prompt caching for large document processing:
- Embed the document into the prompt: Include the full text of the document, along with any relevant metadata or context, in the prompt.
- Specify a prompt cache ID: Assign a unique ID to the prompt cache that will be used for this document.
- Send the request to Claude: When sending the request to Claude, include the prompt cache ID to indicate that the prompt should be cached.
- Reuse the cached prompt: In subsequent requests related to the same document, use the same prompt cache ID to reuse the cached prompt and its associated context.
Reusing the cached prompt enables Claude to swiftly retrieve relevant information from the document without the need to process the entire prompt again.
This efficiency significantly enhances response times, allowing for quicker interactions. Additionally, it reduces operational costs associated with processing, making the overall system more economical.